

















For the Love of ONTAP: NetApp’s Marquee Data ONTAP
Hello. Good morning, good afternoon, or good evening depending on where you’re joining us from today. Thank you for joining me today in this webinar. My name is Eduardo Rivera. I work in NetApp IT and I manage a team that we call Customer-1 Solutions Group. Talk a little bit more about it in a second. But today, what I want to do is talk to you guys a little bit about our use of ONTAP within NetApp IT and our experience with this marquee product that NetApp sells. We know that today, NetApp has a lot of different products, right? That we talk a lot about things… that other tools and things we have the cloud and whatnot, and all those things are technologies that we do manage. But at the end, ONTAP keeps playing a major, critical role in our infrastructure.
So as customer of the solution, my goal here is to cover really three things with you today. One is I want to show you where those fundamental, I’ll say, core technologies of ONTAP that still provide quite a bit of value to our infrastructure and our applications that we serve. Two, I want to discuss a little bit about how ONTAP has modernized and is really serving new workloads and, as you’ve heard of our product in the news, of how we’re going to the cloud and really evolving the role of this operating system. Then three, I’ll touch a little bit upon what has been the transformation as administrators, and storage administrators particularly, going into this new world of cloud and things as a service and how have we adopted in the light of that.
So as we go through this discussion, I want you to think about your own environments. Perhaps think about how you may be taking advantage of some of these features, even things you might take for granted today, and perhaps how you may want to take advantage of all the new stuff and all the new features and functionality today that you may not have explored yet. So with that said, let me get started.
NetApp IT Customer-1
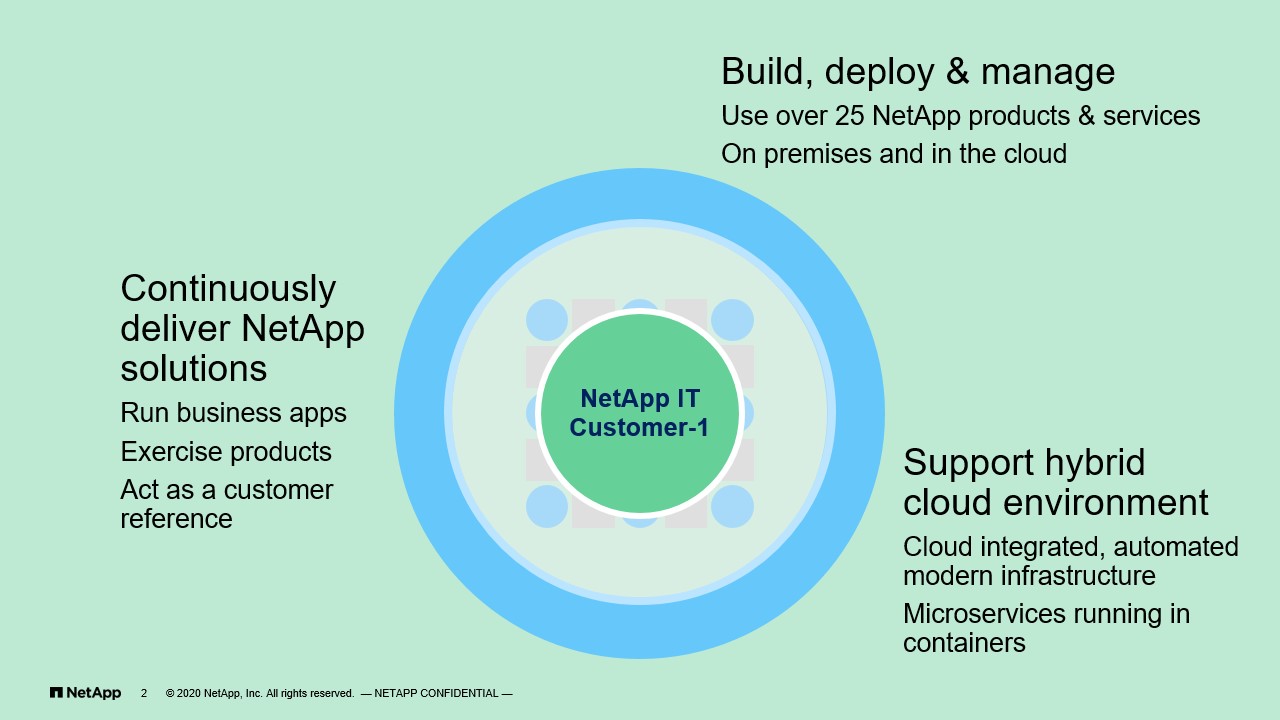
As I said, I manage a team called Customer-1 Solutions Group. But what is that? Well, at the end of the day, we’re a group within NetApp IT that is responsible for deploying and managing all the technology infrastructure that is NetApp technology that supports business applications and run internally. So I guess you can think of us, although we manage many different things, we can think of us also as a storage team. Right? We manage all the storage arrays that sit in our data centers, we manage things that sit on the cloud and in between, and we also manage all the tools and whatnot that come along with that. But because we are a, I guess, a consumer of NetApp technology within NetApp itself, we call ourselves Customer-1 because we are often consuming these solutions early on and we also using our experience to talk to our product teams and our customers about things that work or don’t work, providing best practices, providing, again, various suggestions and improvements within the products that we use.
Of course, for me, as a IT organization, I will consider ourselves a large enterprise organization with On-Prem, Off-Prem, then everything else in terms of presence of infrastructure. Now, with all that in mind, the realities of the guys that work in my team are all ultimately, well, by training, storage administrators that have grown up to do things as well. Because today I was here to talk to you guys about ONTAP, I thought that it would be a good idea to just ask them, “What do you think about ONTAP?” What are the things that they like about it?
What do I like best about ONTAP?
So that’s what we did. We asked some of our members to express what features do they come to mind whenever they think about ONTAP and the way they manage it onsite. These are some of the things that they said. I don’t think that these are surprises, right? But I think you see a collection of features that you probably are well familiar with, things that have existed for a long time, and some that are evolving. Right? I’ll touch on a couple of these things. We see mention of things like Snapshots, SnapMirror. These are things that have been there for a very long time, but they continue to defer value.
At the same time, we see a dimension of REST APIs and automation around ONTAP. Even encryption to some degree, right? These are things that have crept in in the last few years where the focus has been, I will say, doubled down on those features. We spent a lot of time doing things like building automation to manage the systems, automatic healing, if you will. We think a lot about security. So ONTAP has had big impact. Just the operating system and what it can deliver has had a big impact on the way that we are able to manage and maintain it over the time. So I thought that was interesting to see their reactions. I wonder what you on the phone may be thinking.
Customer-1 Solutions Group Portfolio
But let me just take a step back for a second, right? So we’re talking about ONTAP today, but let me give you some perspective. I said from a Customer-1 perspective, we manage a lot of different things, right? Basically everything that NetApp technology that is in our IT organization as well as a collection of programs and initiatives that we have built to maintain the infrastructure. As I said, I’m not going to go through down the list here, but when you look at the gamut of things that we are covering, we’re covering traditional infrastructure items like ONTAP, StorageGRID, HCI. But also there’s tools and there’s a whole bunch of programs that we created, things like automation program or security program. Life cycle management. So these are some things that we have build and maintained and run the business, if you will.
On the other stream, we also are trying to learn new tricks, right? The reality is that as we sit in this environment and new technologies are rolled out, things like containers and container orchestration and automation and the cloud, we cannot be oblivious about what’s happening in those areas. Those are things that are important for us to understand so we can continue to serve them with the infrastructure that we maintain.
ONTAP
Well, with that, let’s talk about ONTAP. In the case of ONTAP, it does play, as I said, a major role in our infrastructure. It is the largest footprint of technology that we support today. As we look at the numbers, this is what it looks like.
ONTAP Environment by the Numbers
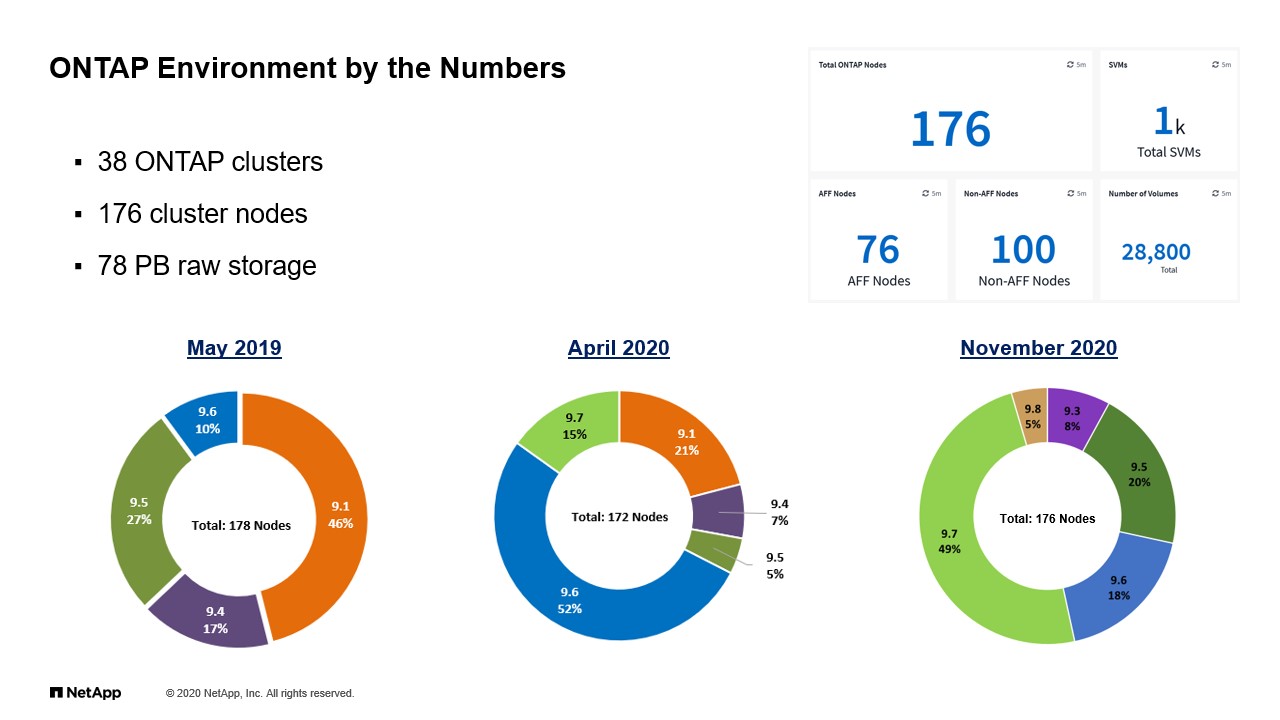
As I said, we consider ourselves an enterprise sized organization. We have a decent amount of clusters spread across multiple physical sites, across actually the world, as well as the presence on the cloud and others. Now, there’s a lot of numbers on this slide, but I guess what I wanted to leave you with is that we have a healthy ONTAP environment. We also have a diverse environment even within ONTAP. We have a good amount of all flash arrays, a good amount of traditional FAS systems, hybrid, I guess, systems, we call it these days.
The interesting thing in there is that as time go forward, we certainly have been more forward buyers, I’ll say, of all flash FAS technology for all primary workloads. While we still buy some FAS hybrid, that has been relegated to secondary, dev test environments and certainly our backup infrastructure. So we’re still buying on those sites, but really our primary work has end up more and more often on the all flash array.
Then to add to this, although it’s not clear in this picture, we also are starting to deploy a lot of CVO or Cloud Volumes ONTAP, which is essentially an older version of a filer just sitting on the cloud, right? The other thing to note here is that as we move throughout the years, we are always in a constant cycle of upgrades. You can see here, I mean, this is a year and a half worth of data. But we’re always upgrading ONTAP. We have an ongoing program that manages this. The point here is to always stay modern, to take advantage of the latest and greatest features, and also really cycle through infrastructure.
We’ve already gone through at least one… We’re now in the second life cycle cycle of cycling out old nodes from our clusters and bringing in new nodes. This is where you all move everything to a new nodes, you get rid of the old ones, now you can upgrade to the next version of ONTAP. So we’ve done that now a couple times and it’s, again, a way to keep the environment fresh and, again, possible through some of the features that ONTAP provides. As you can see, as I said today, we are pretty aggressive in terms of upgrades, right? We are now over, I guess I’ll say, almost 50% 9.7, but already introducing 9.8. You’ll see this donut kind of change shape as the months and weeks go on, now heavily targeting 9.8 growth.
ONTAP: Evolving with the Times
But the interesting thing about ONTAP is that although I have been managing ONTAP, I think, for, I don’t know, it must have been 10 plus, 12 maybe years, is that it has been wildly successful to manage our traditional infrastructure, our databases and whatnot. At the same time, it has evolved with the times, right? Now, it’s not about ONTAP just on the all flash arrays or flash arrays, it’s ONTAP on the cloud for cloud volumes ONTAP, ONTAP as a service through CVS or cloud volume service, as well as ONTAP select and stuff with defined environments. So we’ve had a flavor of ONTAP on all these areas. I don’t think it stops here. I think you’ll see more evolutions of this ONTAP technology be pervasive across many of the portfolio items that are continuing to release. So it really is a story about a evolving data operating system that continues to be very relevant and really very important and critical to our infrastructure.
ONTAP Balances traditional and modern workloads
One of the things that ONTAP is doing really well, I guess from our opinion, is that it really does a really good balancing act. Right? Which is a tall order, right? On the one hand, we still heavily rely on all these traditional features that we’ll talk about in a minute to support things like databases and VMware infrastructure and all this operating system technology that’s been around forever. But on the other hand, we now have a growing need to support more, I’ll say, evolutionary, revolutionary, modern infrastructure. Things like On-Prem and Off-Prem, but also containers, container orchestration, the modern architecture of applications, the need for self-service and integration into those orchestration platforms, which leads always to models of cloud and DevOps that we like to talk about these days. So that’s where I mean when we talk about ONTAP being able to serve traditional and new infrastructure demands. Again, we see that day in and day out in our IT infrastructure.
Core ONTAP Strengths
So I want to talk a little bit about those traditional demands and those core ONTAP strengths. Now, it is almost impossible to give an exhaustive evaluation of every single feature that ONTAP has, so I’m going to pick through a few areas that have been important to us at NetApp IT and which I think are certainly very valuable. I’ll give you some examples as well. So that’s what I want to do in this next section.
Traditional workloads
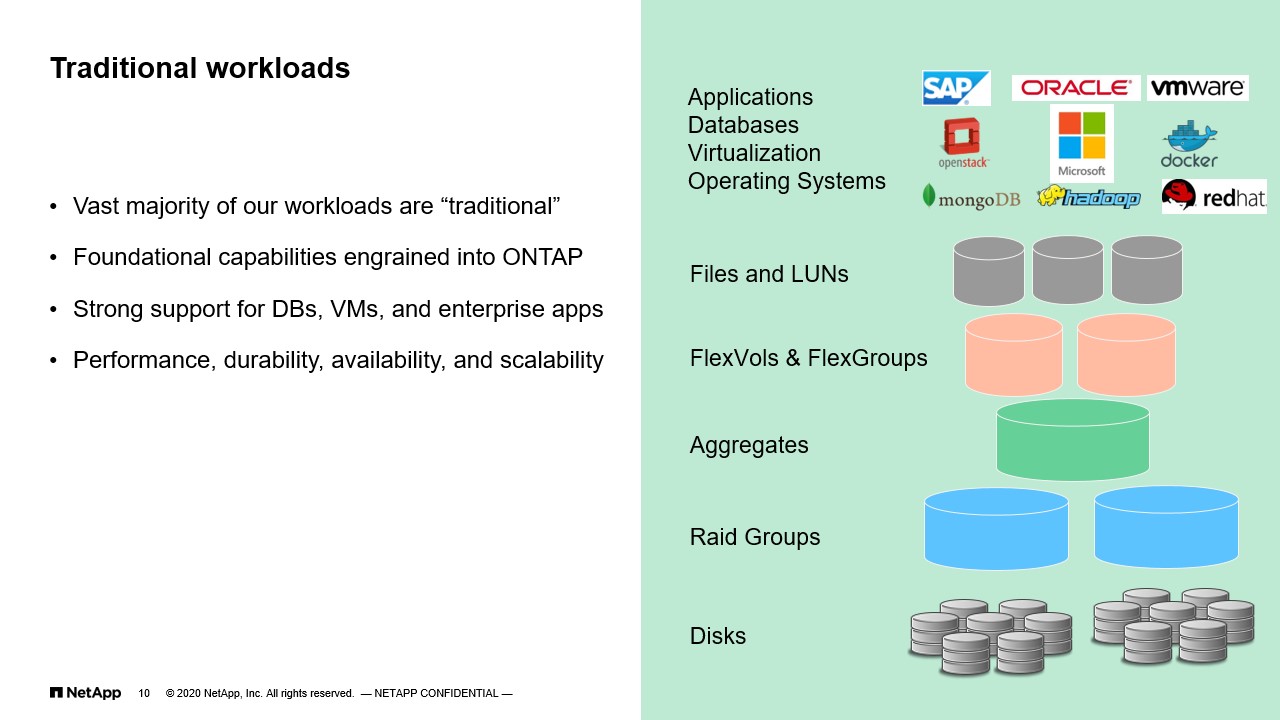
Starting with traditional workloads. As I said earlier, what do we mean by traditional? I’m thinking about Oracle databases, MySQL databases, MS SQL, VMware infrastructure, operating systems. All this, SAP, et cetera. All these things that typically run in enterprise data centers mostly On-Prem for the most part and now things are going on the cloud too. But all this tried and true pieces of middleware infrastructure that require high performance, high reliability, scalability. This is the bread and butter, if you will, of the ONTAP strength, right? We build WAFL many years ago, which allows us to create this obfuscation layer between disks and raid groups and aggregates and ultimately flexible volumes that provide all these data needs. But what it does beyond that is really provide, again, a reliable, high performance, and scalable environment.
To be frank, the vast majority of our On-Prem infrastructure, that’s what it is. It’s a lot of Oracle database, SAP environments, applications that just one, either LUNs or NFS shares to go and rewrite data as fast as they can, as reliable as they can, with an understanding or perhaps an assumption that it’s always on. Right? There’s never any disruption. That’s what we’ve been able to achieve with ONTAP.
Multiprotocol support
Now, those same environments, and this is something that I think we take for granted very often these days, those same environments are not necessarily one color, right? Meaning that they don’t always want a LUN, they don’t always want a iSCSI LUN, a fibre channel LUN. Sometimes they want a NFS share or a CIF share. I think we take this for granted that the ONTAP environments that we have built, and this is true for every single cluster that we have supported, that they are multi-protocol. We can support any protocol all on the same system, all on the same cluster, right? Now that we’re talking about modern day ONTAP, it’s all about the cluster environment.
What else that allows us to do? It really allows us to really maximize a value of that infrastructure. We find ourselves not even thinking… As we remember, a long time ago, those wars of well, is it block or is it file, whatnot? We don’t even think about that anymore. It’s like what do you need? Do you need a LUN? You get a LUN. You want a NFS share? You get that too. They all come in the same system and all we need to worry about is how much capacity we need to allocate, what type of node, et cetera. So we’re not fine tuning or dedicating systems based on protocols anymore, which kind of eliminates a huge silo that, say, 10 years ago wasn’t the case. We had a lot more, I’ll say, debate of, well, how do I best allocate things? Now it’s just put it all in the same pool and let it sort itself out. Again, it sounds very basic, but it’s a huge advantage and a huge value for us.
NetApp IT experience with ONTAP
Just like that, the other thing that we’ve been take for granted is the abundance of efficiency technologies that are present in ONTAP. We don’t often look at them, to be honest with you. I did have to look this up for this presentation. I knew that we’re doing well. I didn’t realize how well we were doing, right? What I’m show you here, these are numbers from NetApp IT. Through compression, deduplication, cloning, Snapshots, et cetera, the reality is that we are presenting over 1,000 petabytes of use capacity, if you will, logical use capacity to all of our clients. But when you look at the physical usage, that 1,000 plus petabytes is really about 25 petabytes, right? So it’s a drastic reduction on the physical infrastructure that we need to satiate all of the needs of our obligations.
More than a 45X reduction, I mean, that’s impressive, but I think what it tells me is if it wasn’t for these technologies, that again, they just kind of work in the background, they’re just kind of there, if it wasn’t for these technologies, I don’t think that we could afford to build the storage infrastructure that is needed to support all these demands. I think, to me, it’s super interesting and it’s super rewarding to see how well things are working behind the scenes with regards to efficiency.
FlexClone Approach
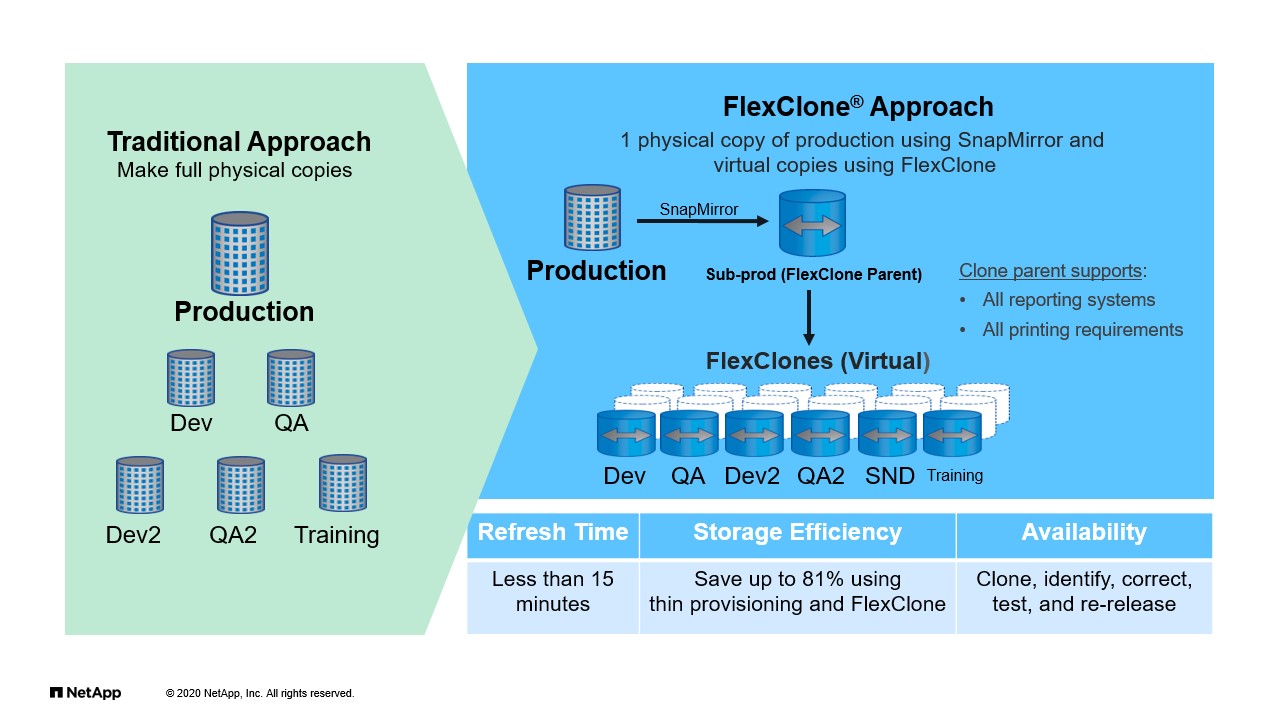
Speaking of efficiency, the other technology that we use day in, day out, and again, it’s all those things we probably don’t even think about anymore, is FlexClones, right? FlexClones have been the foundation by which we build the Dev test, Dev2, test two environments based on single copy of data, right? Typically the way that we have set up in NetApp IT is we’ll have production environments mirroring data to sub-production environments. We call this the separate clusters, right? We kind of have a nomenclature that the terms was production and not production. Then from that copy, we create 10 copies of that to create all the development environments, test environments, whatnot. This is a traditional value play for ONTAP that has been true since the day I even started working with ONTAP 12 years ago or so, maybe 13 years ago, and it continues to be true today, right?
So when we were building new environments, there’s always an assumption that, yeah, we can clone it, we can create copies, we can do all sorts of things. Why is that valuable? It speaks back to the efficiency, right? So one copy of that data can be 10 copies of it to do testing, DR, recovery. Right? Perhaps something happened to the original dataset and we need to recover something interest eh past using an older Snapshot. We can clone that and create a writeable version of that volume to go ahead and troubleshoot. This is probably, again, something that we take for granted, but what I think is mostly important about the way that we’ve done it with ONTAP is, well, the creation of all these clones come with no performance penalty and they come with no real storage utilization.
Of course, as you use the clone things, they start to diverge from the parent and there’s space consumed, but they are immediate and they are immediately not performing impacting and not space compacting. So we can create a lot of these copies without any kind of problem. Beyond that, they look and behave and work just like any volume. Guess what? If you like it and you want to keep it, and you move somewhere else, you can split it. It’s incredibly flexible. So powerful for what we do every day within our environment.
Automated Non-Disruptive Upgrade (ANDU)
Just as powerful, is being also, I’ll say, the delivered promise of easy and non-disruptive upgrades. I think that was a huge deal, especially when we’re moving from, I’ll say, 7-Mode environments to cDOT, where now we are talking about a cluster of not just an HA pair, but it could be up to 24 nodes in that cluster and managing upgrades throughout a large ecosystem. The improvements that have been made within ONTAP itself to, for instance hand over control of aggregates from one node to another to reduce any kind of impact to ongoing IO, but to couple all those under the hood and improvements as we go into the cluster with the process of this, what we call, ANDU or Automatic, Non-Disruptive Upgrade.
What is that? If you’re not familiar with it, it’s essentially a way that ONTAP manages, or the way you could manage, I guess ONTAP upgrades if you’re not using it, is as simple as just downloading the code, stitching it in on the cluster. There’s a validation step where it will verify that your cluster is healthy enough that there is no gotchas, if you will, in terms of incompatibilities within your version. You download, you validate, and then you just kick it off. When you kick it off, it just goes node by node by node upgrading to the latest version of ONTAP, validating that it was successful, and moving on to the next.
From an operational standpoint, that’s exactly what we do in NetApp IT. For all those upgrades that we talked about a few slides ago, they’re all handled through ANDU. We kick it off and we just kind of wait for it to be done and we get a message at the end and we’ll move on to the next. So it really has streamlined. That’s really what’s made possible managing such a large fleet of filers and keeping them up to date. It really is, again, another big value for us.
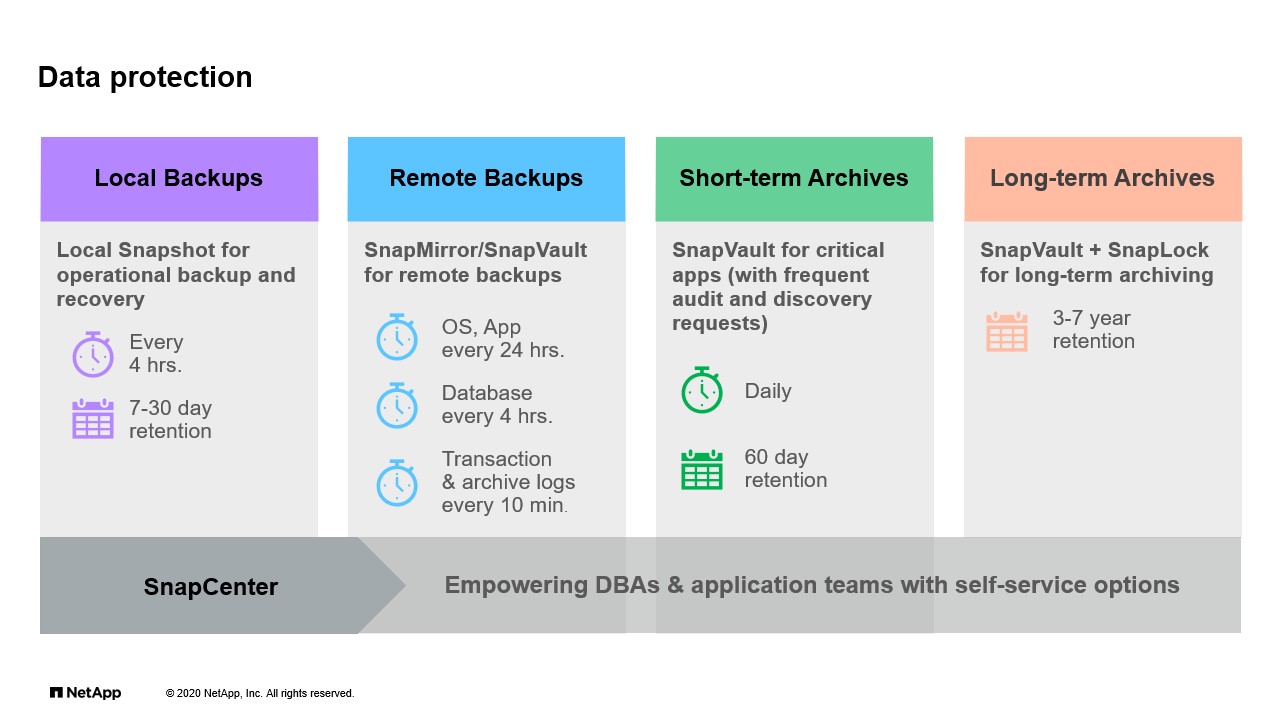
Data protection
Moving onto another, I’ll say, cornerstone of ONTAP is data protection. I think of all the things that we do with ONTAP, the mostly used feature is always Snapshotting, right? You probably don’t even think about it these days. There’s Snapshot schedules, you’re Snapshotting by default. It costs nothing, right? It’s just about just creating a whole bunch of Snapshots and managing and you can create policies that roll them off. It’s almost costs you more not to Snapshot because it’s such a insurance policy against anything that can go wrong with a volume that it will make no sense to me nowadays to have an enterprise grade storage infrastructure component without a robust Snapshot technology.
So as such, we use Snapshot all the time. Every volume that is on the floor on our infrastructure is using Snapshots. They all have a schedule that they follow. Beyond that, we then take those Snapshots and those volumes and re-replicate them. There’s also our cycle level of protection there. So we’re using things like SnapMirror to replicate from point A to point B and keep a secondary copy for a little bit of time. What’s the length kind of depends on the application. But let’s say somewhere in the order of 30 days we keep that rolling copy somewhere else. Beyond that though, we also employ SnapVault. Now we’re looking at Snapshots using SnapMirror in some cases, SnapVault in other cases to maintain an isometric set of Snapshots at this destination. If you’re not familiar, when we do the SnapVault vaulting, it’s really the idea of being able to keep a longer set of Snapshots on that secondary copy, essentially vaulting them, than what the primary volume has while on the other hand, SnapMirror really keeps an equal set of Snapshot-able size.
With the short-term archiving, we’re able to maintain longer periods of time and provide this additional protection. But then we take that and in some other cases, we have legal requirements to maintain longer backups. When I say longer, I’m meaning years, right? So in those cases, we’re then implementing technologies like SnapVault and SnapLock together. So SnapVault creates the copies of our volumes and Snapshots in our destination system and SnapLock ensures that those Snapshots are locked in place for a set number of years. You can set it in such a way that there is no way to get rid of them until they expire. This is what they call, perhaps, WORM radar right? Write One Read Many and it’s locked in time for you to be compliant with whatever legal requirements.
Now, across this scheme of data protection technologies that we’ve been using at NetApp IT, we’ve also introduced the use of SnapCenter. This mean as of a few years ago at this point, but I’ll say it’s more on the newer side, right? Snapshot’s been there forever. SnapCenter being around for probably a couple years. But SnapCenter has also empowered our DBAs, VMware administrators, and others to manage of these flow of Snapshots and protection and provide that self-service data protection management to some of those middle-ware infrastructure teams that perhaps know better how to backup and restore data on their own databases and infrastructure.
Modern Evolution
So as I said, there’s a lot to be said about ONTAP and core features. I just talked to a few of them that are interesting to us and I think they’re very valuable. But I also want to pivot now and talk a little bit about what we see as newer use cases. I’ll say modern evolutions. This is the slide, right? Newer things that we can do with ONTAP that are also catering to growing needs within the infrastructure.
Adaptive Quality of Service (AQoS)
The first thing that comes to mind is this notion of Adaptive QoS. If you’re not familiar, QoS is Quality of Service. It’s a feature that was introduced early on in the cluster data ONTAP. But I think it was not until 9.3 or so that Adaptive QoS comes along. What it allows us to do is really create this dynamic policies of QoS that attach to each volume and they maintain a particular ratio of IOPS per terabyte or megabytes per terabyte if you prefer doing it that way. But at the end of the day, is that why are we doing this? Because we’re trying to protect against any kind of Boolean workload or otherwise random workload that may have an impact on other running environments.
I think AQoS is something that we use religiously across the board. Every single volume has it turned on and it not only protects us against those Boolean workloads, but it also protects us, or ensures I’ll say, that we can deliver a particular level of performance consistently to everybody else. So if everybody in a particular cluster is set at a QoS setting that is reasonable and deliverable by the system, then everybody can expect to be guaranteed X amount of IOPS per terabyte and that’s what we tried to do. So it allows us to build a service of performance within our systems themselves. Of course, it’s all automatically managed, so we don’t really have to do any kind of manual tuning.
Storage Service Levels
When I talk about the service levels, and this is more on the QoS, is something that, again, more of the today, we like to talk in terms of building performance tiers instead of issuing out an array or a particular LUN or a particular type of drive. We want to build performance tiers that our workload can expect to have. This is again powered by QoS and Adaptive QoS. The way that we have been doing that with our ONTAP infrastructure is that we have defined certain aggregates and nodes to be able to deliver certain levels of performance. Then we guarantee those levels of performance, but the implementation of Adaptive QoS and the enforcement of that. So it allows us to really shift the conversation from hey, you’re going to put that database on an all flash array or flash array to hey, how much performance are you need for that workload?
This is important. Why? Because it not only this allows to create a service level within the infrastructure that sits On-Prem, but it also allows us to set that mentality, that cloud mentality, because that’s how we consume resources on the cloud, is based on tiers of service. So it starts to create that hybrid approach, hybrid feel of how we look at infrastructure.
Provisioning and Maintenance via Code
Now, the other thing that I see as modern is really all the automation work that’s been happening with everything, right? Nowadays, we all talk about DevOps and the cloud and this and that and the other. Well, ONTAP has really, I’ll say, evolved to the point where we are trying to define everything we do within the system through code. I mean, of course there’s still things that we do by hand these days, but that’s al, I’ll say, a transition period. I see a future for us where everything from creating volumes and SVMs, et cetera to maintaining all these options on the clusters are just going to be driven through automation. My team here at NetApp IT, we spend a lot of time building Ansible automation as playbooks to do everything from what we call Day 0 Builds, which is configuration of new nodes and clusters, to building simple volumes to SVMs to maintaining standards such as Broadcast Domain, naming conventions, and things like that. So we can do almost everything through the creation of code.
This is a little bit of a preview of what I’ll talk in a few slides, is like we also been trying to brush up on new technologies like Ansible. Right? So NetApp has created a set of Ansible playbooks for ONTAP which have facilitated a lot of this automation. At the same time, NetApp has released REST APIs starting, I think, on 9.6. I mean, that’s where it first came out, which would lend itself for you to create any kind of code that wants to manipulate, I don’t know, programmatically ONTAP. So as we move forward into the future, this ability to manage ONTAP through code is what allows us to really integrate ONTAP into these orchestration layers of the higher of the stack that allows for self-service and other types of automation.
FlexGroup Volumes Addressed Active IQ Ingestion Problem
Another technology that has been very beneficial to us has been FlexGroups. In this example, I’ll talk a little bit about Active IQ. If you’re familiar with NetApp solutions, Active IQ, previously known as the auto support, right? We have the need within NetApp to ingest a lot of data from all the systems that sit on the field. That data comes in the form of either they posted the HTTPS or emails. We get all this information from all these systems in the field and we have to save them somewhere. Well, it used to be the case that all that ingestion would happen into, again, some manifest volume that sits in our data center and those FlexVols were not keeping up with a growing need of out support that will often fill up, we will have to spend time getting a new one, mounting on a million different servers and do the ingestion. It was a big to-do every time. That process of cycling through volumes got to be more often and more often as more systems start deployed and the scaling kept going up.
So that’s where we introduced FlexGroup. That happened maybe at this point two years ago. We introduced the use of FlexGroups to replace that flexible system that we had. With the FlexGroup, we essentially created this huge pool of volumes across multiple controllers and presented as one single bucket, if you will, where all these AutoSupports are now coming in. What does that allow us to do? Well, we don’t have to be changing volumes every time anymore. We can grow this FlexGroup where a FlexGroup has a limitation of 100 terabytes, the FlexGroup is 20 petabytes, right? So we’re growing much larger and not only in capacity, but also in I/O node count. So we can continue to ingest millions and millions of files that come in.
The other results that came out of the transition to FlexGroup has been that we have increased performance. Right? Now the constituents that make up the FlexGroup are spread across multiple controllers. We have the aggregate of throughput of those controllers, therefore we can ingest more and reduce the processing time of that ingestion process. So it increases performance, it eliminates a lot of manual effort, it is easy to manage. When we combine all the FlexGroup technology with the efficiencies that we mentioned earlier, we are seeing some incredible savings, especially in the compression side. Across all the constituents, we’re seeing… Well, it says here five to one. I think it’s more like six to one compression that we’re seeing these days. I think the logical size of that data is on the order of like about 21 to 22 petabytes while their physical usage is 3.7, 3.8 petabytes. So it’s a huge delta between the logical size and the physical size. Once again provided by those efficiencies.
Securing Data Infrastructure in NetApp IT
The other side, another thing that we’ve been spending a lot of time here, is security. There is a lot of focus on security. There’s always been, but I think more so these days with all the threats that we see coming out the internet. Luckily for us, there’s a lot of technology that has been built and continues to be developed within ONTAP to deliver the security needs. Within NetApp IT, I mean, this is partly a sampling of a few. There’s more than this. But within NetApp IT, we’re looking and we’ve been implementing some of these for a long time. Some of them, we’re looking to in the near future. But we’re certainly in tune, if you will, with the IT security team and what that they want us to be looking out for.
For instance, today there’s a lot of focus on ransomware, how do we protect against that. Well, that for us is a combination of Snapshots and SnapMirror and SnapVault to protect against a potential multi-pronged attack, if you will. We also have a lot of focus on creating what we call Secure Multi-Tenancy, but real secure where we have a particular cluster that we have a SVM on a separate IP space from this other SVM. There’s an IP space so there’s no way that they can communicate or create these other gaps between deployments. We also have done this forever, right? Like setting audit logs to certain central log management systems so they can be evaluated and processed. As we move forward into the near future, we’re most likely going to be rolling things out like MFA to control any sort of accessing to our system.
So the focus on security has never been greater. ONTAP as a technology really has grown up with it. It’s more important even today that not only we’re trying to secure things On-Prem, but Off-Prem. Right? Things are sitting on the cloud. That’s where things like encryption are even more important than they are if they just sit in your secure data center. So a lot of interest there, a lot of value for us in that area.
Modern Integration into the “New Stack”
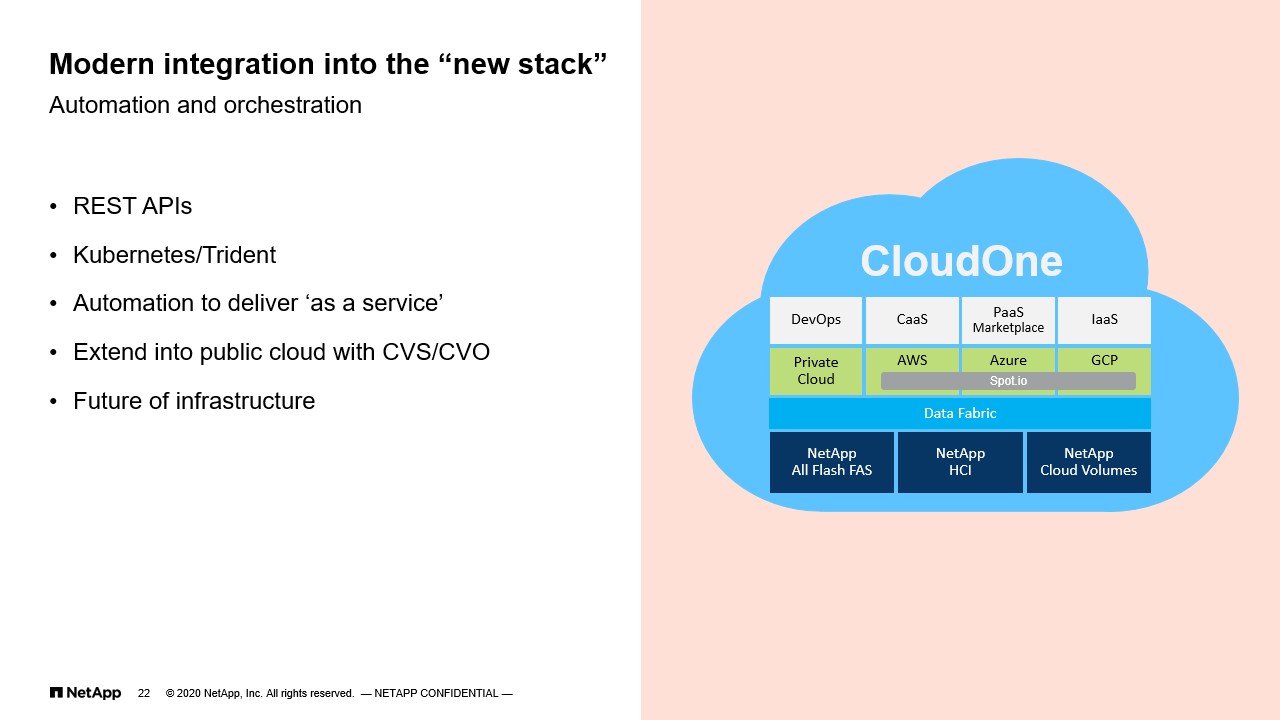
With that, I’ll talk a little bit about the new stuff. So we touched upon some of these topics as I covered in the past slides, but the reality is that when we look at the future, the future is about dynamic workloads. It’s about cloud, it’s about containers, and it’s about everything as a service. Right? What I mean by that is infrastructure as a service, platform as a service, container as a service. The ability for us to deliver at the touch of a button or a click of a mouse somewhere on a form a complex set of infrastructure components including storage. This is where within NetApp IT we had this umbrella, say, brand of what we now call CloudOne and this is what we’re building internally to satisfy our own internal customers, our application teams and whatnot that want to consume our services.
Within CloudOne, what it really runs at the middle is automation. We have automation driven through ServiceNow integration, Ansible integration, Kubernetes integration, which comes in different flavors, but today we use a lot of OpenShift. That integration ultimately has to make its way to ONTAP to create volumes and create dynamic resources. For instance, when we talk about Kubernetes, we’ve been using Trident for a very long time at this point.
Trident, if you’re not familiar, is essentially a storage orchestrator that lives inside Kubernetes. It’s created by NetApp. It allows you to do the dynamic provisioning of volumes as they’re requested by containers. Right? So a container exists and it’s a volume. It has stuck to Kubernetes or OpenShift in our case and OpenShift needs to go and grab that volume. The only way that OpenShift knows to grab that volume is by talking to Trident and then Trident needs to have the permissions in our clusters to create and destroy volumes at will. So now we’re putting together a couple of things, right? We have automation. I have security because I’m jailing, if you will, Trident into a particular SVM with its own set of security protocols. But we’re also hands off in the way that I’m letting Trident be its own administrator of that infrastructure. Again, it delivers it as a service as has been requested by the user.
So you’ll see that as we move forward, there’s many needs to have this integrated storage platform with all these modern infrastructure components. The same thing can be said about what we’re doing with CVO and CVS. We’ve also integrated Trident with CVS. We would be looking to integrate CVO with some of our infrastructure as a service offerings, which are not Trident-based. They’re mostly Ansible-driven automations where we want to deploy computing to cloud with storage in the cloud with Ansible stitching it all together.
As we look at the future of what I see, the reality is that we’re going to spend less and less time managing, as administrators, managing individual volumes and all the things that probably have driven our jobs up to this point. We’re going to spend less time doing those minutia of components within the array, taking a step back, letting the orchestrated platform manage them, and we will worry more about creating the automation and creating the controls around that that allow for this ecosystem to live. Again, this wouldn’t be possible if it wasn’t because of the hooks and the technologies that are now being built into ONTAP. This is how, in my opinion, ONTAP continues to be relevant, not only to deliver value in the traditional site, but on this new stack, if you will, that we talk about.
The New Reality for Storage Teams
Which turns into my final point and one thing that I wanted to touch upon, is that as we see, as ONTAP administrators, and as we look at the future, we see a new reality for storage teams. I think there’s a little bit of concern of how do we retrain, what do we do as we step back away from being the obsessively tooling volumes and what not, and the first thing that I think that the new modern era of infrastructure brings to the table is that we have to recognize as infrastructure providers, as storage providers, that the customer, while we still serve those traditional environments, DBAs and application owners, I am less and less serving those individuals directly and I’m more serving the automated platform in the middle. I am building storage infrastructure that will be accessed really by things like Trident or by Ansible or by Python or PowerShell or some other orchestration tool that allows them to reach in, a user to indirectly reach into my system, and grab the resources that they may desire.
So we’re trying to build automation and the controls around that. As I said earlier, we are trying to learn new tricks to be able to define our infrastructure through code. That’s just our reality, right? So that’s number one, is we need to understand that the customer is changing. The customer of the storage platform is changing and we need to cater to it.
Number two, of course, for us to be able to do that, we need to embrace this notion of infrastructure as code. We need to embrace the notion that we have to add a few new technologies to our repertoire. We need to know how containers work. We need to know how CICD works, how coding works. We need to start developing… It not to mean that we need to go out and create… We’re not application developers, but we need to approximate some of those other practices to be able to define our infrastructure through code, to be able to save our standards in code and be able to be dynamic to be with the time. So we need to learn a few things, we need to add those ancillary skills to our repertoire so we can be successful going forward.
In closing, as I said and as I’ve said through all the presentation, ONTAP for us has been evolving with the times and we are trying to do the same along with it. It has really been enabling this balancing act between maintaining the traditional infrastructure, but also reaching out into modern infrastructure of stacks, whether they’re On-Prem or in the cloud. With that, I want to thank you today for your time and happy to take any questions. Thank you.