















Agenda
Hello everyone. Let’s have a quick overview of today’s agenda. First of all, we are going to talk about why we choose Veeam solution followed by architecture diagram, there is three StorageGRID, Veeam backup process overview, Veeam storage backing infrastructure. And then we do have storage backing infrastructure which covers E-Series storage for Veeam repository.
So let’s move on to why we choose Veeam.
NetApp IT chose Veeam
Veeam is a backup solution like other vendors. Veeam also provides a backup solution. It can perform backup, restore, replication. Along with that, there are additional features such as application of a backup for critical apps such as active directory, SQL and the MS exchange. So Veeam is a partner solution for NetApp. Veeam, again it’s a solution which can integrate with all our NetApp product such as StorageGRID, Element OS, HCI, E-series and now ONTAP. So it’s an image and file level backup support.
It is agentless and very easy to manage and administer. We don’t need a storage administrator to configure or install and manage the entire Veeam backup infrastructure solution. So it also have granular backup resource solution, which makes it easy for all the administrator who can easily handle it and it reduces the complexity of all your backup infrastructure with the VF source side compression and the deduplication. It has got more capabilities than your native backup solution. So when we talk about compression, so we get by default, we get the optimal compression with the LZ4 format, which also provide us a two is to one ratio of compression. So it is fairly light CPU or hit on all your infrastructure component, which gives excellent throughput the rate of 150 Mbps for your backup, as well as even we get a faster decompression rate.
And also we do have the deduplication, which reduces the amount of data that has to be stored on your disk by detecting redundant data within the backup and storing it only in once rather than like multiple blocks. So Veeam deduplication is based on identifying the duplicate blocks inside the single Veeam disc or across multiple Veeams inside the same job. So we have all these good futures, which gives us a value for having a backup infrastructure for HCI. And along with this NetApp HCI we don’t have like a certified inbuilt native solutions from NetApp. So as a partner solution we chose Veeam for our backup infrastructure. So at the moment we do have deployed Veeam backup solution in two US data centers within HCI infrastructure, which is serving 1400 VM backups.
Now let us a review or architecture diagram.
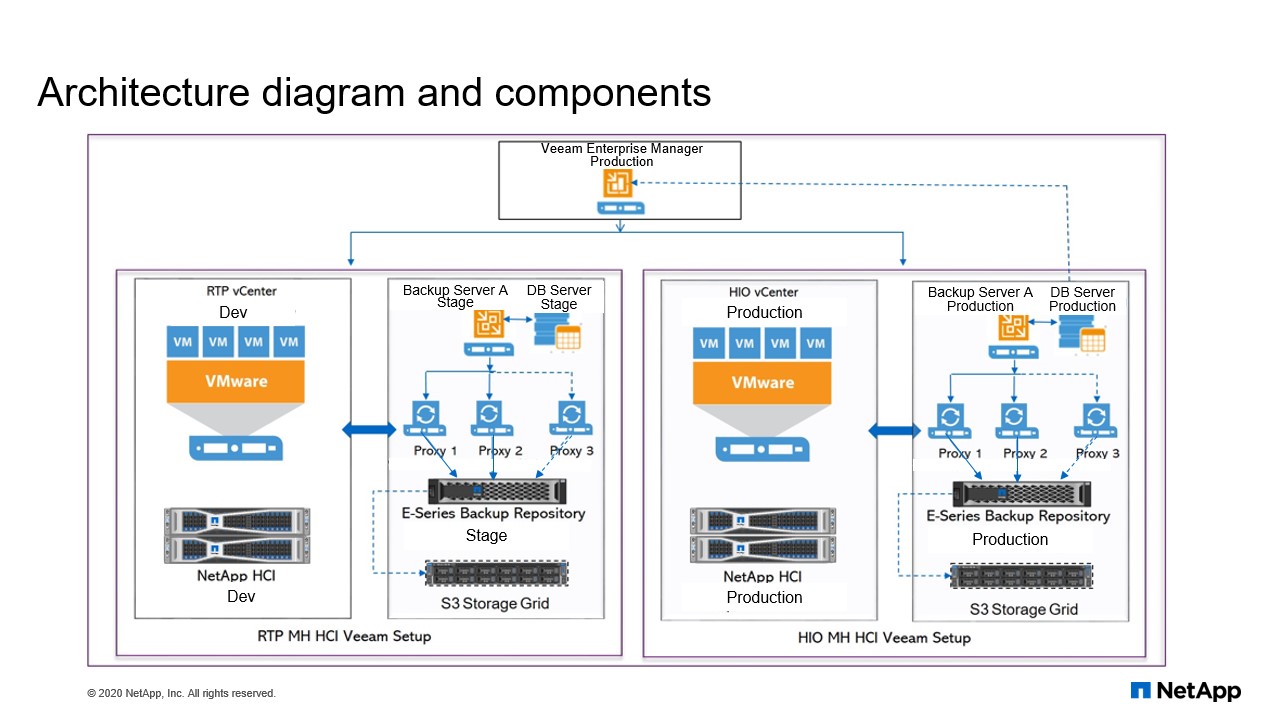
Architecture diagram and components
So we have like core component from Veeam backup setup. So which serves all your backup jobs. So which provides a backup infrastructure to your HCI infrastructure. So when we talk about two data centers, there are two data centers in the US which is one for production and another one is for support. So let me talk about support data center. So we do have HCI infrastructure, which is hosting all your virtualization environments and which is using the SolidFire as your backend storage. And on top of SolidFire storage you have the hypervisor, which is serving Veeam workload. So now like to get this backup, we have configured Veeam backup infrastructure using some of the component. We got a license, Enterprise license, which goes backup manager, enterprise manager control along with that wean repository and we can also to expand to a StorageGRID like we are using a Scale-Out repository.
All these are covered within our license. So we do have some additional component which we are not using at the moment today. So let us talk about individual component. So we have Veeam backup manager, that’s a software, it’s installed on the windows machine. So basically it’s a configuration or control center, which maintains all your scheduled backup jobs and it controls all your tasks, what it has to be run like for which Veeam and what are the types of proxies you’ve got, what backups you’re running, how many VMs Everything is controlled from your backup manager and it maintains the database within your DB. That also we have used a SQL DB and within that entire configuration database is managed. And then next coming to the proxy, the proxy is… it’s again, architecture component. That’s it between the backup server and other component of your infrastructure.
So proxy server like, when you talk about backup manager, it administrates all your task. It controls all your task. When it comes to proxy it process all your jobs and it delivers backup traffic to the rest of the infrastructure component such as backup repository, which is needed for storing all your data. So now let us move on to storage repository, right, backup repository. So on the backing we are using E-Series storage for all our infrastructure backup copies. So now there is talk about backup repository. Once again, this is installed on your windows server. So we are using windows 2016 for all the backup infrastructure components and we are purely installed on windows base. We can even definitely use Linux operating system for the repository, but backup manager and a SQL that’s a core, requirement on which has to be installed at the windows server.
Now repository, that’s a storage location where Veeam keeps backup files, Veeam copies and metadata off all your replicated VMs are placed. So metadata when we talk about metadata, when you’re trying to replicate your backups to remote locations, so obviously you should maintain the metadata that will be stored in your primary repositories. So which maintained by being repository server. Now let me move on to the additional component. So we do have the additional components such as Veeam ONE which we are not using in our infrastructure since we do have additional monitoring parameters like we do have Zenoss or Splunk or other tools which can integrate with entire Veeam solutions. Veeam also provides a REST APIs which can be used within your infrastructure depending on your needs. So now like that’s a reason like we have not been using Veeam ONE which is monitoring and entering the analysis purpose within Veeam backup infrastructure. Now we are using Veeam Enterprise Manager, that’s serve as a single interface where you can manage or control all your jobs.
It’s a single pane of glass where you can see multiple backup infrastructure setups. And along with this we do have the Scale-Out repository, like we talked about the three StorageGRID, so that’s like Scale-Out repository.
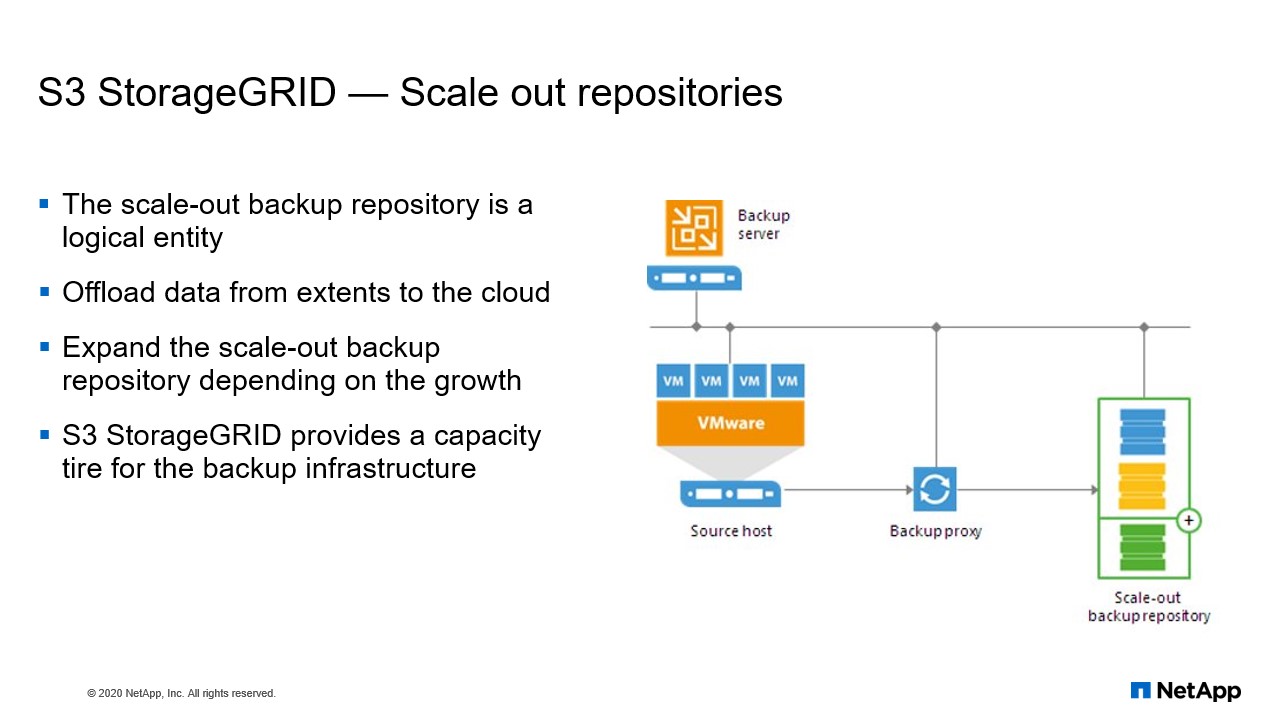
S3 StorageGRID – Scale out repositories
Scale-Out repository is kind of extending your repositories depending on your growth needs. So today you have a repository of 30 TB from the E-series. If you want to grow more you don’t need to go for again E series instead like you can use Scale-Out repository to extend your existing repository. Adding as in extent. The Scale-Out repository is a logical entity, it groups several backup repositories called the extent. When you configure the Scale-Out backup repository, you actually create a pool of storage devices and system summarizing their capacity. For long-term storage, you can use the backup replication to offload the extents to the cloud.
So you’re basically like keeping your offline backups within other storage rather than keeping it on your primary storage infrastructure. So we are going to offload the extends to the cloud. Now expanding the Scale-Out backup repository, we can expand our Scale-Out depositories depending on growth at anytime. You don’t need like we should be doing it when it’s reaching the capacity or even without reaching capacity you can extend or like even shrink the capacity depending on your needs. So a three StorageGRID provides a capacity tier for your entire backup infrastructure. So, which gives like a better value for your overall backup infrastructure.
So let me stop here and we’ll take some question and answers if there are any.
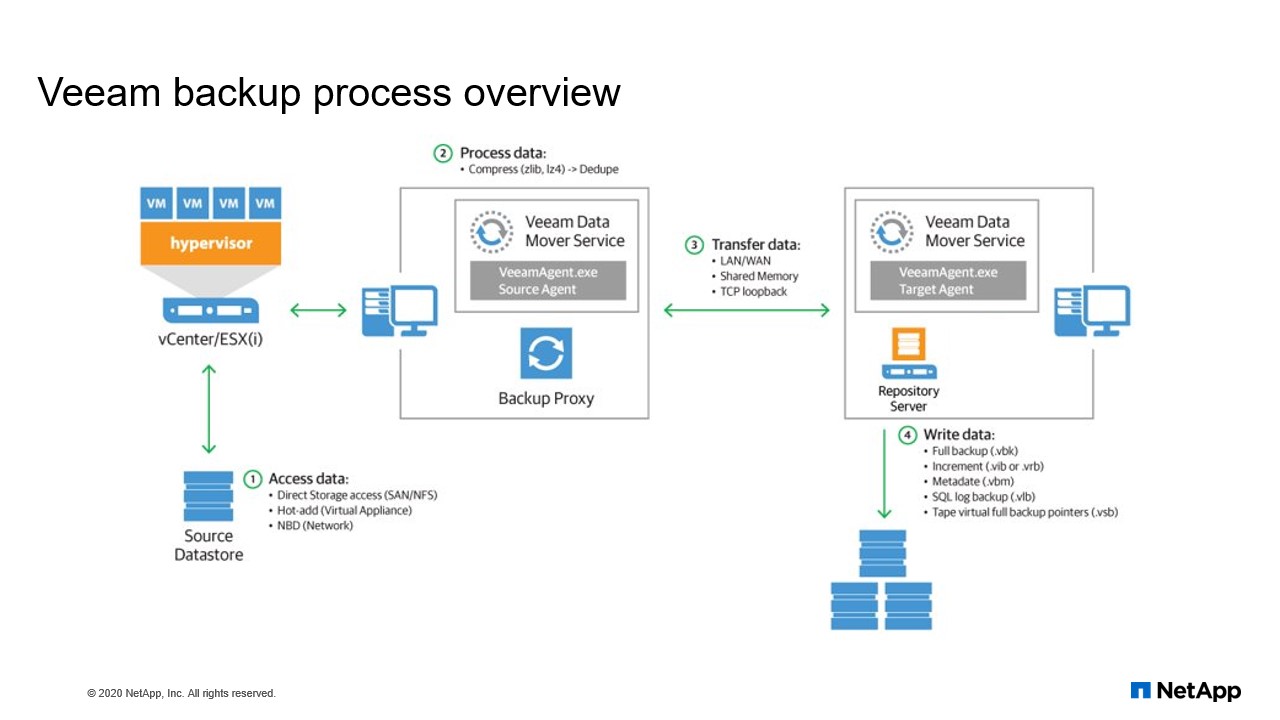
Veeam backup process overview
Now we are going to talk about Veeam Backup process, or Veeam. In the previous slide we discussed about the architecture diagram and some of its core component. In this slide, I’m going to discuss about the core component of your Veeam infrastructure, how it is going to integrate with your HCI infrastructure to manage all your backup solutions.
As we discussed about it, in the back-end we are using SolidFire for our storage, which serves on your ESX data server. Then from Data Source, we have all the VMDKs. It’s a VMDK running through SolidFire. Now, let us discuss about Veeam core component again. In detail, how exactly it works the backup flow. It happened from Backup Manager to backup proxy and how it interacts with vCenter to manage your backup. Again, how exactly transmit to the repository servers and what are the action items it does?
When we talk about the backup jobs… Earlier we discuss about the core component in Veeam Backup Manager, right?. That’s like your controller, which manage or administer all your jobs. When your new backup job session starts, Veeam Backup Manager reads all your job settings from the configuration database and creates a list of Veeam tasks to process. For every disk of Veeam’s added to the job, Veeam Backup and Replication creates a new task for each VMs. It’s an individual task. Again, it creates, even though its job is having multiple VMs, for individual VMs and again within the VM treats each disk as another task. So once it creates a task, Veeam Backup Manager connects to the Veeam Backup Service which is installed on your Backup Manager Server, which is Windows-based server. The Veeam Backup Service includes the associated dueling component that manages all your tasks and is also seeing the backup infrastructure. The associated dueler checks the backup infrastructure. Resources are available and decides the proxy.
So by default within your job, right? When you create a job, you will assign the proxies and the repositories. So for processing any task, these are the mandatory things which you should have. Or before scheduling your job, you should have the repository and then the proxy server which interact with multiple layers and then get the backup copies. So once you have this backup proxies in the back of repositories to process your task, Veeam Backup Manager connects to the Veeam transport service on the target repository and backup proxy servers. So it interacts between these two components. And then the Veeam transport service starts a Veaam Data Movers on both the sides, one on the backup proxy and on another one on the backup repository. So you get a Data Mover, which source at the destination which coordinates each other with the data sets.
So your new instance of Data Movers is started for every task that the backup proxy is processing. So Veeam Backup Manager queries information about VMs and virtualization host from your broker service, which is again like we call it a server-side being an agent, right? So once it gets the list of your VM and the virtualization host, it collects all the information. How much the server-side data it is needed and again on the repository it evaluates the data spaces available to back up your metadata. Once all this information is validation is done. If the application aware image processing is enabled, we talked about in the architecture diagram, if you have the application aware backups, you can easily get the application level restoration tasks for such as application active directory, SQL or even Exchange so you can restore your any user objects within active directory.
If you delete it by mistake, any user content that also you can restore it, application aware backup. So if you have that processing is enabled on your jobs, Veeam Backup Replication connects to the VM Guest OS, operating systems. It deploys the runtime process on VM Guest OS. Once you have the run time process, it performs in guest processing task to evaluate what is happening or what is running to take the backup content. If you don’t have it, it processes the job, so only it works when you are using aware application or backups. So Veeam Backup and Replication request to the V-Center to create a VM snapshot. So it uses the VM via vSphere technology to get the data in terms of a snapshot. So when you initiate that task VM snapshot task VM disks are put into the reader listed and every virtual disc receives a delta file and all the changes that user makes to the VM during the backup, are returned to the delta files.
So now what happened? The source VM Data Movers reached the VM data from the read-only VM disk and transferred the data to the backup repository in one of the tasks or more. During the incremental job sessions, the source VM Data Movers uses the Changed Block Tracking method. So this is really needed, right? When you’re doing an incremental job. So what was your previous date and what are the changes has been done with the current backup. So to retrieve those data records, it uses a VM Data Movers uses the CBT, we call it a CBT, Changed Block Tracking, to retrieve only those data blocks that have changed since the previous job session. If the Changed Block Tracking is not available. So if you’re taking your full backup, if you don’t have anything right? If nothing is modified, then obviously it just goes with a blank session, right?
There’s no changes happen and it just updates the metadata file. So if there are any modification is done, it tracks those. What are the change happened, right? Change Block Tracking it captures those information and it updates your backup repository metadata file. So if the Changed Block Tracking is not available, the source VM Data Movers interacts with your target VM Data Movers on the backup repository to obtain the backup metadata and uses this metadata to detect blocks that have changed since your previous job sessions. So it all depends on what sort of backup you’re running, whether it’s full backup or incremental backup. If it is an incremental backup, it tried to evaluate your block, whatever it is modified in the previous backup, only those things, it’s gets tracked. So when transferring VM data from the source, VM Data Movers performs additional processing again, so it filters out your zero data blocks.
So we talked about the deduplication. So again, like reduplication, it evaluates your zero data blocks and block off flat files and it excludes all the VM guests to it’s files. So the source VM Data Mover compresses the Veeam data and transfer it to the target VM Data Mover. After the backup proxy finishes reading all your VM data. Still you’re talking about the backup proxy. All the processing is happening because VM Backup Manager, it controls your task and then it pass on to your proxy. Right? Proxy is trying to interact with when your repository and the VM center infrastructure to read all the processing task. Right? So now once you have the information it gets the data from the server-side by even compressing the data and it transferred to the VM Data Mover. So after backup proxy finishes all you’re reading the data, Veeam in backup replication requests the V-Center server to commit the VM snapshot.
It did not commit the snapshot and we had the read on the emails, right? So now the Delta file will be deleted and it will be committed. And VM will run through your normal application. So with this we are using the deduplication, right? It removes zero blocks, block files of your FAT files and blocks of excluded VM Guest Files. So with this we are able to save a lot of data and then finally it most to your repository. It depends on your type of job. If you are doing your full backup, the repository will get a VBK file and if you’re using an incremental job, we are going to get an incremental GIF file. And in case of application aware, again, your secret log backup will get a VLD. So with that the entire process is driven from source to a destination repositories.
I hope you guys have understood the entire process, how it works. So let me, since we don’t have a demo session for this webinar, I’m going to show some of the slides and exactly how it looks within the backup jobs, right? When you’re creating it schedule backup job. How does it look? Let me just go through the next slide.
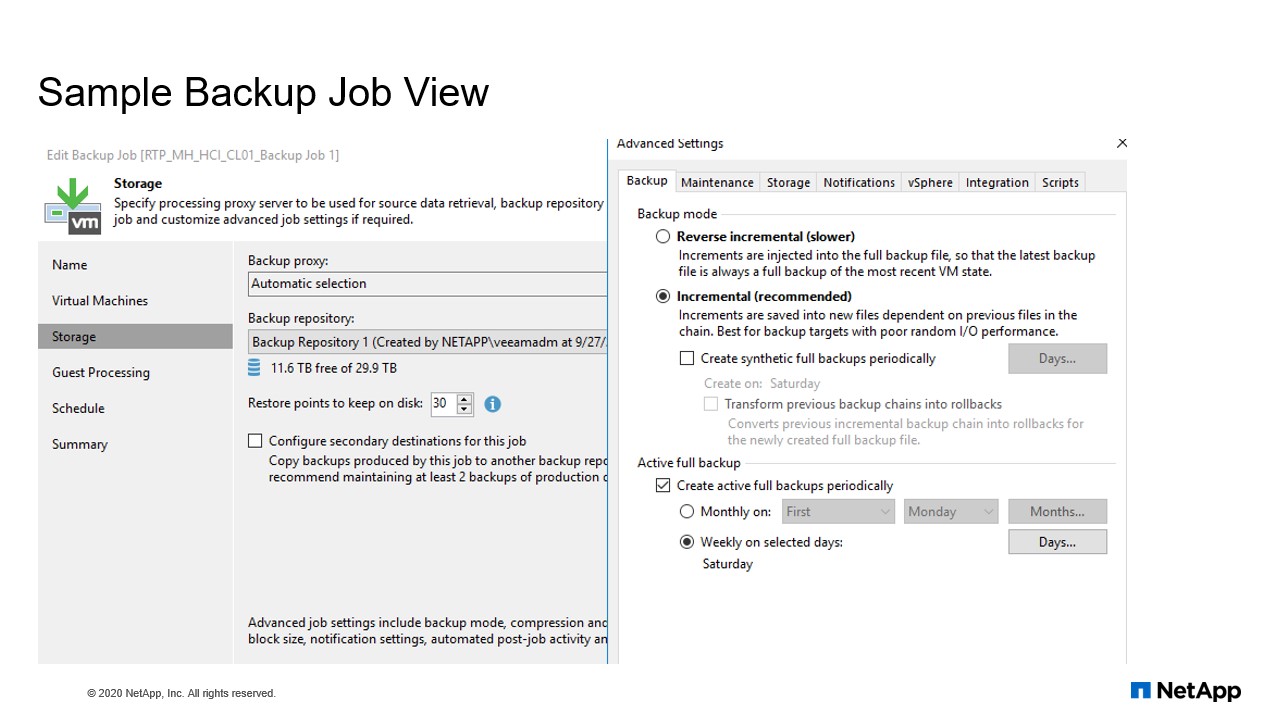
Sample backup job view
I’m going to show you a sample job view. So when we are scheduling a sample backup jobs, we definitely need to provide a proxy selection. And before that, you need to select your virtual machines, how many virtual machines you’re choosing. Once you have the virtual machine’s content, you can choose your proxies and repository. So you can even see how much spaces are really built within your repository and how much restoration points you’re going to keep. So if you’re trying to link the daily one snapshot, if you’re retaining it for 30 days, so you can specify the restriction point of 30. Whether you’re doing an incremental or there was incremental and if you’re using any full backup. So in our case, I give an example, right? We are using incremental on a daily and every Saturday we’re running a full backup.
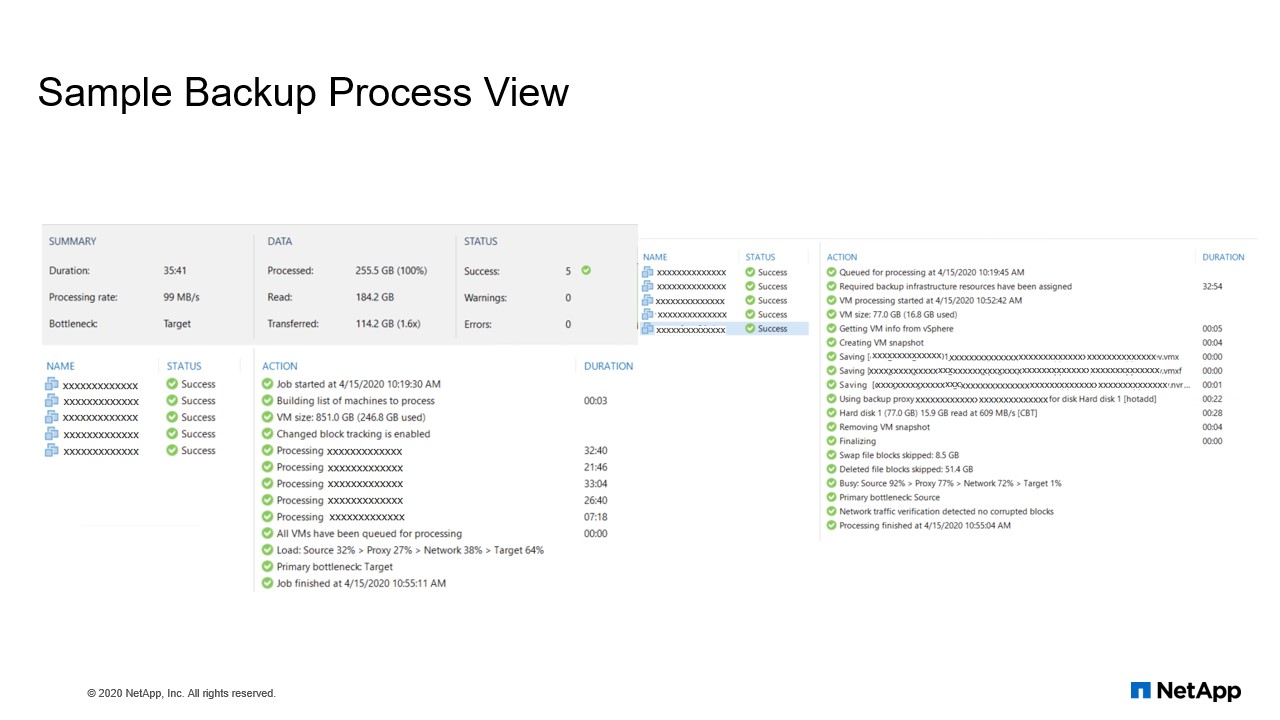
Sample backup process view
And we talked about the process, right? So when we initiate a backup job, it evaluates all your VMs and it gathers how many disks are running on each VM. So it evaluates the size of your data. How much size for each VM it has. Suppose I have extracted a snapshot for five VMs, we executed a job. So the overall VM size is 851 GB, out of that it tried utilizing the CBT, Changed Block Tracking is enabled on this job. So it utilize CBT to validate what of the contents is modified. So obviously it has a got to 46 GB out of eight 51 GB allocated space and then it started processing the backups. And again we talked about it evaluates even the network throttle, how much it is from the proxy or which layer you have a bottleneck, it evaluates all these things and then it processes your job.
So if you look at a single VM, what exactly happen? So the backup and processor resource have assigned. Once it is assigned a proxy on repository, it start processing for individual VM, which is a size of 77 in our case in example, what I have to select it and it went to the VM-ware and it collected a snapshot for all the VMD case. And then if you have multiple hard disk, it will go to the multiple hard disks and then take a snapshot and then it start processing your CBT. What are the changes happen? And they tried to remove this block files like zero block files or flat file or guest OS. Once everything is done, the data gets processed and it creates an image. After creating an image it removes itself a delta file within your VM Center.
So once everything is processed from the V-Center to your backup infrastructure, the backup job gets executed and the data file moved to the repository. So that’s an overall view, how exactly it works.
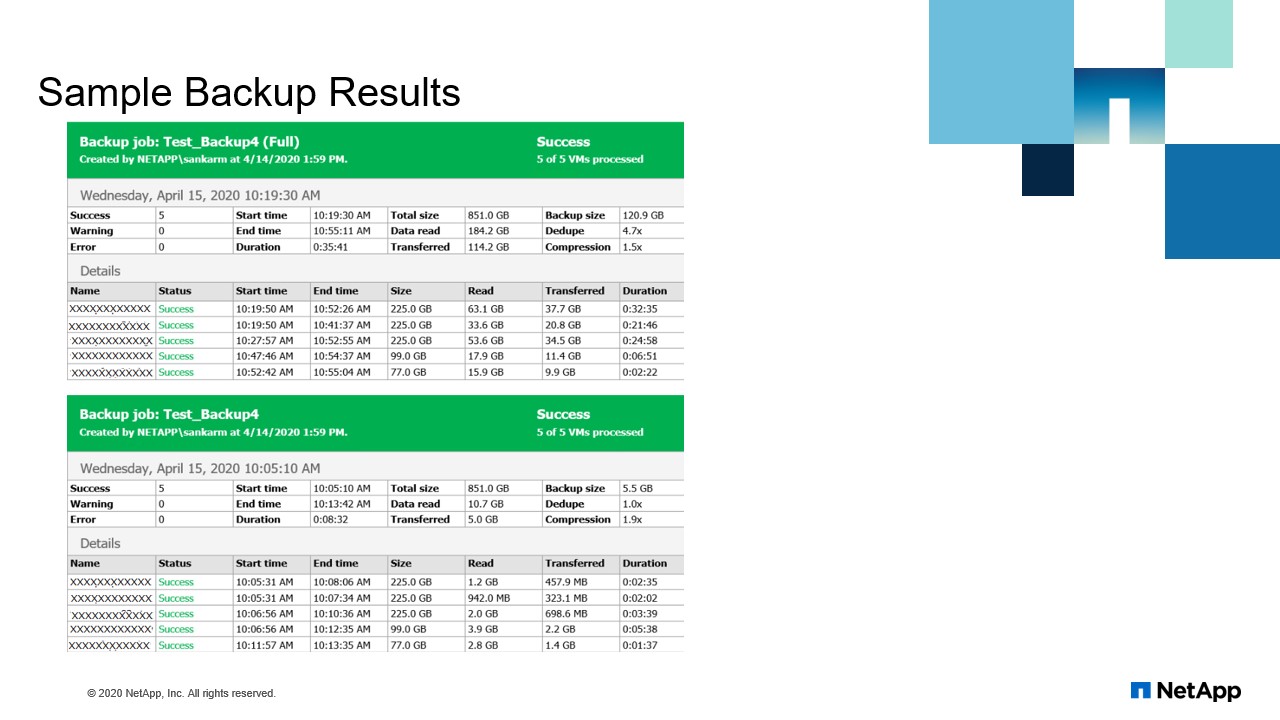
Sample backup results
We can see in the results here. So in terms of backup execution, so it did evaluate your size. So when we started over a VM capacity was 851 GB and the data modification data-read, it was around 184 GB. But out of this, the data transferred is 114 GB. So the overall capacity of your backup size was 120.9 GB. But the reduplication? It was 4.7 X and also we got to 1.5 X compression. So it demoed on zero blocks successfully and then we were able to achieve a better backup. So this was for a full backup. When you compare to incremental backup, it’s even less. The modification was very less since the data changes was very less. We got a backup size, a 5.5 GB.
Veeam backup repositories
So that is more than two repositories when we talk about repositories, so within our infrastructure we got a multiple repositories from E-Series to manage almost our 1400 plus VMs. Right? So each repository we have selected 30 TB of site.
Keeping multiple repositories is beneficial. We’ll talk more about this, why it is beneficial. So when you’re running in multiple jobs, obviously you can run multiple jobs at a time. You don’t need to have a single job with multiple VMs, you can split the VMs and run through multiple jobs. So in that case you can use multiple repositories and you can write onto the multiple story locations.
Also it gives a better visibility for you in case of any growth point of view if you need, if you’re reaching the limit of your backup repository, you can use scale-out repository or also we’ll discuss. So if you read that limit, you can extend your backup repositories. So as we spoke earlier, in our case, you’re using incremental backup once and active full backup on every Saturday.
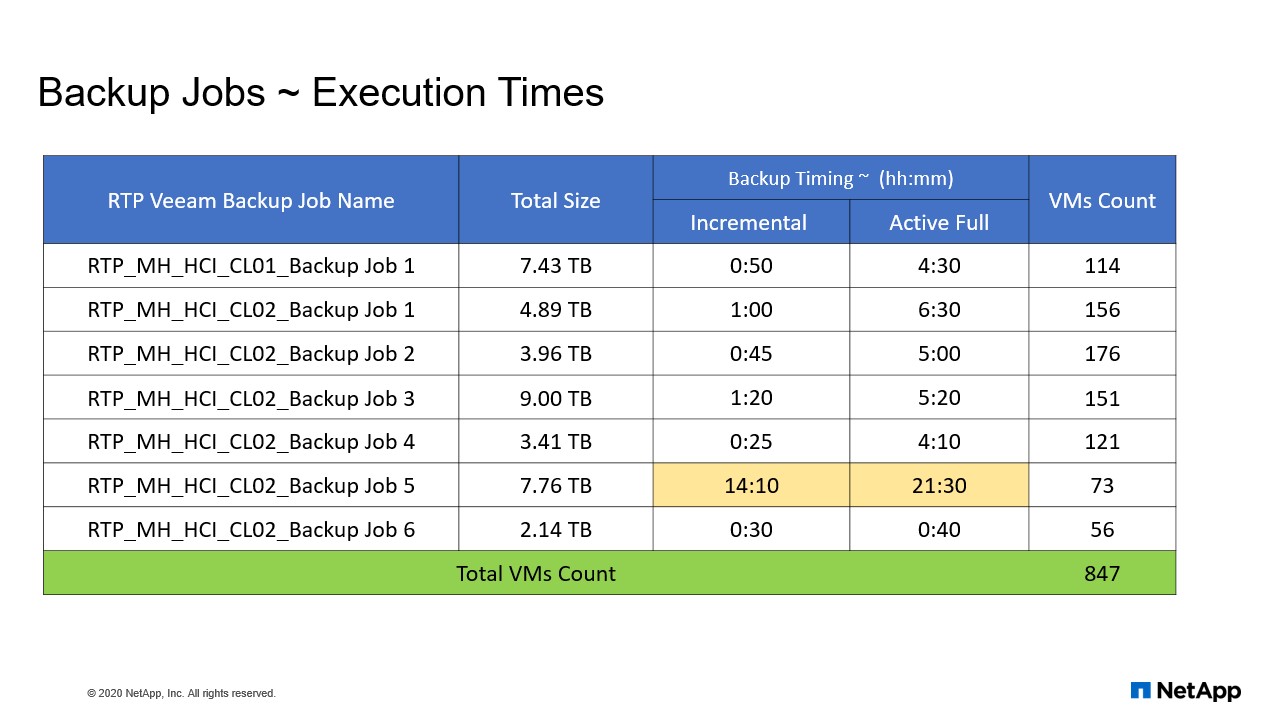
Back up jobs ~ execution times
I have also illustrated some of the backup aggregate and the execution times we have achieved within. Suppose you can see a VM count of 114 which is utilizing 7.43 TB and the active full was four and a half minute, but incrementally took only 50 minutes.
But at the same time there’s one more highlighted. It’s same size. Total size of a VM capacity was 7.76 TB, but the VMs count was 73 but it did take a lot of time because the was written too much. We do have OCI or OCUM applications, which are evaluating the entire infrastructure. It is writing every now and then I write the content on the disk. So that’s the reason we do see there is a huge difference between similar jobs with the similar capacity, but the data is sizes high.
Challenges observed
Now let’s talk about challenges observed. In the previous slides we discussed about the overall backup process using Veeam, and now in this slide we are going to discuss about the challenges. What are the challenges we have observed while implementing overall backup infrastructure for our HCI at both data centers.
So the first thing is we talk about snapshot. So Veeam is utilizing your snapshot technology from the vCenter, right? VMware snapshot to create your backups. So in that case, you shouldn’t have a VMs having already a snapshot. That creates a problem. You will not be able to execute a backup which is already VM is having a snapshot.
And the second limitations, so Veeam is maintaining a limitation backup jobs there are certain VMs can have. Like 200 VMs as a capacity you can say. It’s more than 200 VMs, it will not allow you to create backup jobs.
The third one we talk about VM tagging too. Veeam always recommend you use the tagging method. Within vCenter, you can tag all your VM within an application code. So it helps in multiple ways. So when you’re managing your infrastructure with the VMs tagging, you can back up your VMs using tags. So XYZ, I can take an example. I have an XYZ application. I’m grouping all my XYZ applications with the tag code XYZ. So if I need to back up those application VMs, I simply go to Veeam and create a backup job with the tag identity as XYZ. So by default it pulls all the VMs within that XYZ tag and it devaluates the size. So this is a kind of a requirement to have a backup for all your newly provisioned VMs so you’re adding a new VMs, with again XYZ, you don’t need to come to your backup job and then again modify your list of VMs. You don’t need to do that. Since you use XYZ, it automatically adds your VMs to the XYZ job. And again, while provisioning you don’t need to come here to modify the content. So we take care of it.
And the last point I talk about proxy VMs. Proxy VMs should not require new provisioned backup jobs. So in the previous slides we talked about proxy selection. When you create your backup job, you need to define which proxy are going to select. Suppose you have multiple proxies and you’re trying to choose two or three, like you’re going to specify a single proxy. In that case, the same proxy server should not be a part of that a backup list. So what happens is proxy is your processing unit, right? So you’re trying to create a job backup for your proxy server with the same proxy– which is not allowed. So that’s the reason we always recommend to go with automatic selection. With automatic selection, there are multiple options you’re going to get are like a better performance because processing speed you’re going to get more. And by default, Veeam try to evaluate which proxy is free. And it will allocate from the automatic selection. So these are the challenges as observed, so you can take care of it by configuring it appropriately.
Best practices
So now let us talk about singular best practices, whether having single or multiple repositories, or single or multiple proxies or multiple job share dealers.
So let us talk about multiple or single repositories. So it’s all depends on your infrastructure setup. If it is a very small setup, with less than a hundred or 200 VMs then obviously you can have a single job with single repository, and also you can use single proxy. So you can’t have like… For a single job you can’t have multiple repositories. So you need to run through your backup on a single platform only. So if you have a bigger infrastructure like an enterprise for your architecture, in that case you should always have multiple repositories and multiple proxies for getting a better processing speed. Or you can increase the processing speed with your multiple proxies.
And multiple job share dealers. So you’re already… You can run multiple jobs at a time.. That gives like a flexibility. You’re going to get better performance with a multiple job share dealers.
And also proxy VMs should not be part of the same backup jobs which we already discussed. So that’s a best practice. You can word it like a… You go for an automatic selection and even a job if you are using multiple jobs, just select multiple proxies and use repositories in a proper way. You can construct your entire backup infrastructure.
Veeam restore point simulator
So from Veeam we get the simulator. You can use this tool to evaluate, or you can construct your backup needs by providing your growth rate or what’s your utilization and what exactly you need as part of your restoration points. So suppose you’re looking for 30 days or 14 days. Depends on your retention period. You can evaluate the space needed for running your backups.
So in this example itself, you can see right, I have taken 1000GB of overall data store capacity . The retention of what I’m looking for is 14 days and change rate, how much change rate you’re looking around. So at the moment, for this research and point simulator we choose 10% but in some cases like we do have VMs right, like OCI and OCUM VMs. So in that case the change rate is almost 90% so you can see that it changes very often, right? So it depends on your infrastructure needs. You can take this pattern with us and also like growth, how much you are looking. Per year is it 10% or 20%. So you can decide your requirement and then you can get the results, like how much you need overall space for your repository.
So this tool is a good future for Veeam. So we don’t need to again wait for your storage administrator to validate and come back with the capacity requirements. Instead you can… Yourself you can define what is your need and how much copies you’re going to maintain, what are the various backup option you’re going to use, whether it’s active, full or incremental. These kind of things you can do yourself and you get the capacity requirements needed for your repository in a better way.
So with that, I’m going to move onto next slide where we are looking for some enhancement from Veeam.
Proposed future Veeam enhancements
So this is already placed. This requirements has been placed with Veeam and we are still waiting for their future releases. We’ll see how it goes. But let me talk about what are those enhancement requests we are awaiting from Veeam.
Cluster level backup jobs: So cluster level backup jobs will run all over, a new provisioning, or individually you don’t need to add new VMs you don’t need to create a backup jobs, right? It can automatically, once you have a cluster level backup, it can trigger automated backup jobs depending on the need. Even though there is a limitation, it can create a number of backup jobs. So that’s a future we are looking for. And again the Veeam limitations for backup jobsand we are looking around why there is a limit. So they should either do it in an automated way so that you don’t need to worry about the limitation it can automatically create by its own.
So again, the third point we talked about VM tagging. So VM tagging, suppose again, we talked about XYZ application. It has a 180 VMs. Think about this. 180 VMs as of today, and you’re using the XYZ tagging creator for creating your backup job. So what happens again, tomorrow you’re adding another 30 plus VMs. So does it create an automatic backup job or you have to manually do it. So as of today, we need to create the backup job manually. So this is the kind of requirement, it stops you, right? You got an automated feature with VM tagging. But again, it’s not 100% successful since you hit the limitations. So to overcome this, we need to have a solution. So we have requested Veeam for enhancement. So let us see how they come up with a future enhancement on these things.
So with that, I’m going to stop here. We’ll take some questions and afterwards Victor is going to talk about storage topics, storage and it’s Veeam backup infrastructure components.
Veeam Storage Backend
Good morning, good afternoon, and good evening. My name is Victor Ifediora. I’m going to be presenting the storage backend that is used for this Veeam backup solution for our HCI.
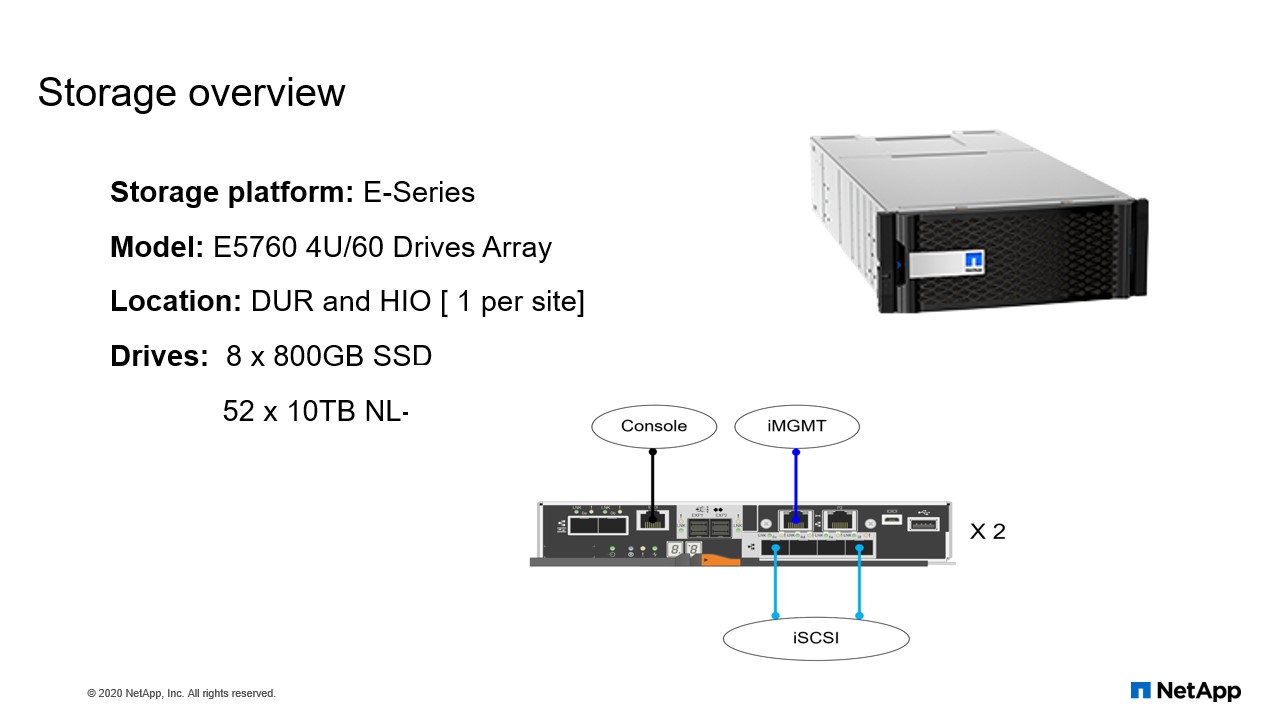
Storage overview
The storage platform that we are using for this solution is the E-series. And the model of E-series it’s using is the E5760 that comes with 60 drives. We have one per site. The 60 drive is made up of 800GB SSDs and 52 10 terabyte drive. For those of you who are not familiar with the E-series, E-series always come with two heads, controller A and controller B.
So, each controller head will have two iSCSI connections that the servers are going to be using to communicate with the E-Series. And also a management interface that you use to manage your E-series. And also, there’s the console that you can use to troubleshoot your E-series in case you cannot get to the management interface.
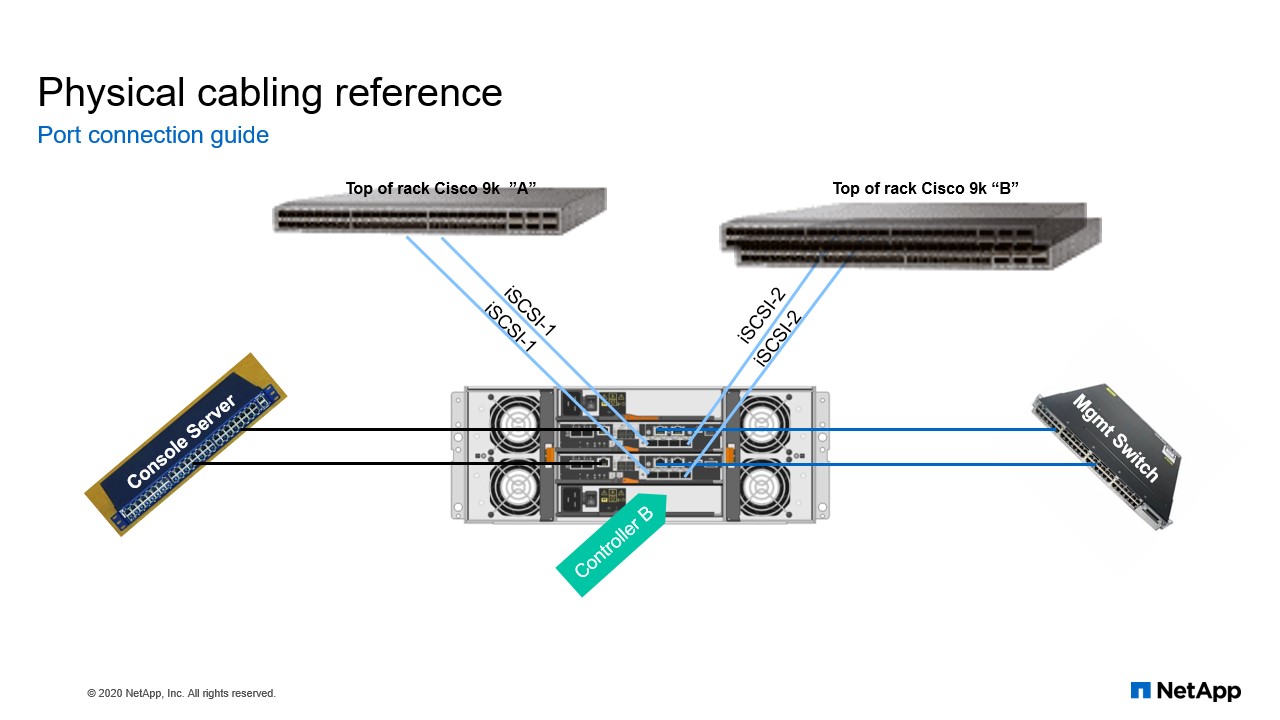
Physical cabling reference
This is the physical connections that we have on our E-series. So, each controller head has two iSCSI connections and it is through these connections that all the servers are going to be connecting to the volumes or the LUNS that are created on the E-series.
For the management interface. The management interface is used to manage your E-series. And you manage the E-series using the system manager. So, whether you use the management interface of controller A or you use the one of controller B, they will take you to the system manager which you can use to configure your E-series or day to day administration of your E-series. We also have the console connection. Like I said before, the console connection is mainly used when you have problems with the E-series and you can’t get to the management interface, then you can connect to the E-series through the console to resolve any issues that you are having with your E-series.
Array settings
For the settings we have on the E-series, we have configured alert on our E-series. Our alerts go in form of email to our storage or operation. And also, we have integrated our E-series with Zenoss. So, what are E-series does, is that our E-series will send a trap to Zenoss and the Zenoss will send those traps to our ServiceNow. And the ServiceNow will use the information contained in the data that is sent to it by Zenoss to create a ticket for our storage operation. And we have also configured the Syslog. So, all our Syslog is forwarded to the Splunk server. For this configuration also we enabled what is called Automatic Load Balancing.
And the Automatic Load Balancing is a feature that provides an automated I/O balancing and it ensures that incoming I/O requests from the host is dynamically managed and balanced across both controllers. So, when you have Automatic Load Balancing enabled, it basically performs two functions. It will automatically monitor and balances your controller resource utilization. It will also automatically adjust your volume ownership when needed thereby optimizing your I/O bandwidth between your host and the storage array.
For access management, we are using the local database on the E-series. You can also configure your E-series with a directory service application like Active Directory and LDAP. But here we have chosen to use the local database to manage our E-series.
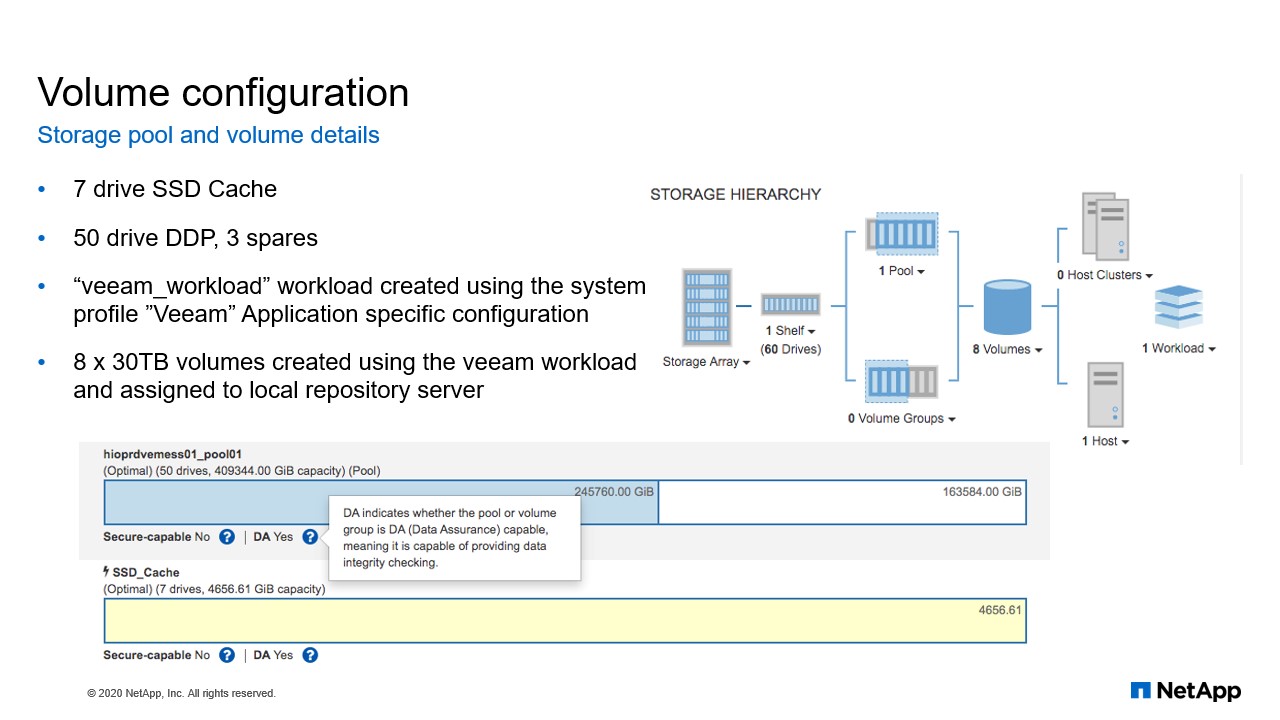
Volume configuration
For the volume configuration. Before you can create the volume on an E-series, you need to create what is called the storage pool or a volume group. For this configuration, we created a storage group and a storage pool. And a storage pool is a set of drives that are logically grouped. You can use a pool to create one or more volumes accessible to a host. So, your host does not see the storage pool. What your host actually sees is the volume that you create on the storage pool. So here, if you look at the picture down here, we have created a storage pool with 50 drives. And also, we created the cache with seven SSD drives. Basically, what the cache is for, is for hot data, data that is accessed frequently. So, any data that is accessed frequently is placed on the cache so that when a host requests that data again, the data is not read from the hard drive.
The data is read from the SSD cache. How does the SSD cache work? When the CPU needs to process any read data, it will first of all check in the VRAM cache. If it does not find the data there, then it will check in the SSD cache. If it’s not found in the SSD cache, then it will get the data from the hard drives. But if the data is deemed worthwhile to cache, then a copy to the SSD cache is sent and that copy is going to be cachec so that the next time the host needs the data, the request is serviced from the cache.
Also, this model of E-series comes with what we called a workload template. So, depending on the type of application that you want to use for your E-series, you can use the workload template to configure your workload. A workload is a storage object that supports an application. The E-series comes with different workload. You have the one for Microsoft Exchange. You have the one for Microsoft SQL. And everything we have done here, the eight volumes we have created, everything we have configured here is from the Veeam workload that comes with this particular model of E-series.
Thank you for reading. See here for the recording of this webinar.